Previously on Lab 001 – Solving a simple use case with Azure Functions – part 2, I created a working prototype of an Azure Function, that queried a public API for a stock price and displayed the result in a simplistic web page.
I finished that post by considering an improvement for the way the prototype works and this is what I will deal with in this episode.
An issue leads to an improvement
The issue with the current code is that each time the function is called, it queries the backend Finance API to get the stock information it needs. In a real life scenario where my Function would be used in a popular application (or being abused in a malicious manner by someone) there might be hundreds or thousands of queries per second. I wouldn’t want to spam the backend API in such a case, so I need to “protect” it somehow.
Since stock prices do not usually change that much from second to second anyway, I reckon that querying the backend API not more than once every 15 seconds (for the same stock) is an acceptable compromise.
So I will modify the logic of my Function to not only show the information it gets from the API but also store it somewhere at the same time (cache it). So, when the Function is invoked, it can first lookup for the desired stock information at the stored data and display this (if it is recent enough) instead of querying the backend API.
Think, consider alternatives, design
I will again start with local prototyping (to work with the problem in a simpler domain) and then move on to applying/fitting the design to Azure.
One easy way to deal with the issue locally is to save the API answer directly to a JSON formatted file. By using a predictable filename, it will be easy to find and read the file in later invocations of the code.
Another way would be to save the information to a table in an SQL database that can be queried later. Or even save the JSON information directly as a document in a No-SQL database.
All options are valid here, since I’m on my Lab doing whatever I want. However, in a real life scenario, the choice depends on the available technology and how the solution is expected to be used in a production environment. How many “pieces” of data are to be saved, how frequently, what are the speed requirements, what are the costs involved in storage and speed, etc.
I will start with the simplest solution, using files for storing the information, and then will see about the rest. If I hit a roadblock, I will reconsider and change the design. Remember, it’s a Lab! My aim is to try things, fail, find solutions and learn in the process 🙂
Using files to cache the information
Looking at the code for the local prototype, what comes first to my mind is how to test the caching mechanism that I will write. I need to make sure that my new code will correctly do the following:
- detect if there is data cached (and not expired) for the queried stock, and
- either return the cached data, if they exist and are not expired
- or query the backend API, return the current data and save them for later
To do so, I will start with a totally fenced test environment, where both the cached and “current” data are fixed, so that only the logic of my code is tested. I did the same with my first prototype code where I used a file to store a sample copy of the API data, to check if my code could find and display the information correctly.
So, how to detect if there’s data cached for the queried stock? I need to somehow keep the timestamp of the last data query together with the data themselves. One way to do so is to detect the cache file modification time. Another, to embed the timestamp in the filename itself. So, possible filenames would be:
SYMBOL_cached.jsonSYMBOL_TIMESTAMP.json
In both cases, the code will need to look if a file that matches the specified symbol exists. But there are some differences in the two approaches. Let’s put them in a table for comparison:
| Metric | SYMBOL_cached.json | SYMBOL_TIMESTAMP.json |
|---|---|---|
| Find the cached file | Easy, direct match with symbol name | More complicated, must pattern match and find the latest file |
| Find if it has expired | Find the file modification time | Extract timestamp from filename |
| Files needed | One per symbol, overwrite each time | One per symbol, but a new one is created each time new data is read from the API |
| Maintenance | – | May need to recycle old files to keep storage low |
| Other | Getting file modification time might be environment-dependent | Get historical data for free, if all cached files are kept |
The SYMBOL_cached.json option seems to be the simplest one, as long as it proves easy to find the file modification time, both locally and in Azure.
The SYMBOL_TIMESTAMP.json option bypasses the need to detect the file modification time, but adds an overhead: dealing with the multiple cache files that will be created.
I’d rather use the simplest option, so I’ll start with that and see how it goes. I don’t need any historical data or to deal with managing the cache size right now.
Test cases for caching functionality
I will need to write some tests for the new functionality. I consider the following use cases:
cache_exists_and_current: lookup for a symbol, cache file exists and is not expiredcache_exists_and_expired: lookup for a symbol, cache file exists but expiredcache_missing_and_created: lookup for a symbol, cache does not exist, it is created after looking up current data
I will create a test for each case. Like I noted before, test data will be fixed, no API will be actually queried.
Disclaimer: There are many aspects to code testing and as more functionality and external dependencies are added to an application, things can get really complicated (and there are tools and techniques to deal with it, e.g. mocking which would become very handy in dealing with a public API). I will not focus on extensive or efficient testing here, I’m just stressing the need to write tests, and trying to show the benefits of Test Driven Development by touching on first principles and writing rudimentary tests. I will probably have to revisit the matter on subsequent labs though.
A deviation worth taking
As I start thinking about how to implement the test cases, I notice several things:
- The new tests have “state”, meaning that they expect some files to exist when they run and also modify/add files themselves. So, I need to write some code that will prepare the test environment by creating the necessary cache files (cleaning up leftovers from previous tests as well) to make sure that tests are repeatable and have the same results whenever they run.
- The caching mechanism looks like an added capability that I might like to turn on and off without changing the interface presented by my stock “library”. The code behavior will change depending on this mode and some tunable parameters (like the cache expiration time) will be needed.
- The code to read stock data from a cache file will probably be very similar to the code that I already wrote to read sample stock data for testing.
I need to deal with the above to control the complexity and keep the code clean.
To deal with (1) I will have to create some test setup/teardown code for my test environment.
To deal with (2) and (3) I will first refactor and clean up the code and then add caching as a transparent capability without changing the existing interface.
Refactoring functions that get stock data
Let’s deal with the code refactoring first, then run the existing tests to make sure I didn’t break anything.
In stock.py, I will change the get_stock_data_from_file function, so that it gets the same parameters as the get_stock_data_from_api function, and calculate the sample filename from the symbol name instead of getting it directly. The expected filename will be of the form SYMBOL_current.json (which should exist). All these will help with testing more symbols more easily.
In stock.py:
def get_stock_data_from_file(symbol, keys=None):
filename = '{}_local.json'.format(symbol)
# ...
def get_stock_data_from_api(symbol, keys=None):
# ...
I will first rename the sample file from test_api_sample_msft.json to MSFT_current.json and change the corresponding parameter in test.py to:
'data_symbol' : 'MSFT',
I will change the tests in test.py like that:
def test_read_file(self): data_expected = self.params['data'] data = stock.get_stock_data_from_file(data_expected['symbol'], keys=data_expected.keys()) for field, value in data_expected.items(): self.assertIn(field, data) # ... same for other functions
I run the tests again to make sure I didn’t break anything:
python test.py ..... ---------------------------------------------------------------------- Ran 5 tests in 0.819s OK
And some more refactoring to clean code
Looking at the functions get_stock_data_from_file and get_stock_data_from_api I see that they have more than one responsibility (which is something that one usually wants to avoid, because it leads to complex code that is hard to follow, test and debug). Both functions:
- connect to the data source, read the data and deal with errors (different code)
- parse the data, find the requested info and return it to the caller (repeated code)
I will refactor the functions to extract the common code in a new function get_stock_info_from_data:
MANDATORY_STOCK_FIELDS = ['symbol', 'regularMarketPrice', 'regularMarketChangePercent', 'regularMarketTime']
def get_stock_info_from_data(data, symbol, keys=None):
effective_keys = list(set(MANDATORY_STOCK_FIELDS + ([] if keys == None else list(keys))))
try:
data_in = json.loads(data)
if data_in['quoteResponse']['error']:
print("ERROR: in response: {}".format(data_in['quoteResponse']['error']))
return {}
data_out = {}
for key in effective_keys:
data_out[key] = data_in['quoteResponse']['result'][0][key]
except IndexError as e:
print("ERROR: getting data for {}: no data".format(symbol))
except KeyError as e:
print("ERROR: getting data for {}: {}".format(symbol, repr(e)))
except Exception as e:
print("ERROR: parsing resonse: {}".format(repr(e)))
else:
return data_out
return {}
I will also extract the source specific code to separate functions read_from_stock_file and read_from_yahoo_finance_api:
def read_from_stock_file(symbol):
filename = '{}_local.json'.format(symbol)
try:
with open(filename, 'r') as f:
return f.read()
except Exception as e:
print("error reading file: {}".format(repr(e)))
return None
def read_from_yahoo_finance_api(symbol):
# prepare url and some headers to keep the api happy
url = "https://query1.finance.yahoo.com/v7/finance/quote?symbols={}".format(symbol)
headers = { 'User-Agent' : 'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:108.0) Gecko/20100101 Firefox/108.0' }
try:
response = requests.get(url, headers=headers)
if response.status_code != 200:
print("ERROR: could not get stock {} data from API: {} - {}".format(symbol, response.status_code, response.reason))
except requests.exceptions.RequestException as e:
print("ERROR: could not get response for stock {} from API: {}".format(symbol, repr(e)))
else:
return response.text
return ""
Then I will rearrange the initial functions to call the new ones:
def get_stock_data_from_file(symbol, keys=None): data = read_from_stock_file(symbol) return get_stock_info_from_data(data, symbol, keys) def get_stock_data_from_api(symbol, keys=None): data = read_from_yahoo_finance_api(symbol) return get_stock_info_from_data(data, symbol, keys)
Nice symmetry! This tempts me to extract the data reading responsibility to a separate Stock Data Provider set of functions, and then inject the desired provider function as a parameter to a single get_stock_data function. That would come handy if I decide to add more stock data providers in the future.
But, I will stop here for now. I may do so later 🙂
Run the tests again and commit the code:
python test.py ..... ---------------------------------------------------------------------- Ran 5 tests in 0.469s OK
Back to writing the new tests
To setup the tests for the cache, I will have to create an environment for each test, with proper cache files. I prepare two such cache files MSFT_sample_cache_hit.json and MSFT_sample_cache_miss.json, with slightly different stock price timestamps. One of them will be copied to the proper SYMBOL_cached.json filename format just before running the corresponding test. I add the relevant fixed data in the test parameters:
params = {
...
'data_cache_hit_filename' : 'MSFT_sample_cache_hit.json',
'data_cache_miss_filename' : 'MSFT_sample_cache_miss.json',
'data_cache_hit' : {
'symbol' : 'MSFT',
'regularMarketPrice' : 255.00,
'regularMarketChangePercent' : 0.1217166,
'regularMarketTime' : 1670014800
}
...
}
Let’s write the first test test_cache_exists_current, assuming that the caching mechanism works. I will also add code to cleanup cache files.
Note: The cache filename is determined at runtime based on the symbol provided. Before removing the cache file, I will validate the symbol name to make sure that it contains only valid characters so that the filename does not turn out to something unexpected. It’s always a good idea to sanitize variables that may contain user input and take part in critical operations.
While I’m at it, I will do the same for the local filename as well.
In stock.py:
import re
STOCK_SYMBOL_ALLOWABLE_PATTERN = "^[A-Z.]+$"
STOCK_LOCAL_FILENAME_PATTERN = "{}_local.json"
STOCK_CACHE_FILENAME_PATTERN = "{}_cached.json"
def is_valid_symbol(symbol):
return re.match(STOCK_SYMBOL_ALLOWABLE_PATTERN, symbol) != None
def local_filename_for_symbol(symbol):
return STOCK_LOCAL_FILENAME_PATTERN.format(symbol) if is_valid_symbol(symbol) else None
def cache_filename_for_symbol(symbol):
return STOCK_CACHE_FILENAME_PATTERN.format(symbol) if is_valid_symbol(symbol) else None
In test.py:
import os, shutil
@classmethod
def clean_cache_for_symbol(cls, symbol):
cache_filename = stock.cache_filename_for_symbol(symbol)
if cache_filename:
try:
os.remove(cache_filename)
except FileNotFoundError as e:
pass
else:
print(f"Invalid symbol {symbol}, will not remove cache")
@classmethod
def tearDownClass(cls):
cls.clean_cache_for_symbol(cls.params['data_symbol'])
# ...
def test_cache_exists_and_current(self):
data_symbol = self.params['data_symbol']
# setup cache environment
self.clean_cache_for_symbol(data_symbol)
# the cache file is just created here, so it's definitely new
shutil.copy(self.params['data_cache_hit_filename'], stock.cache_filename_for_symbol(data_symbol))
# start test
data_expected = self.params['data_cache_hit']
data = stock.get_stock_data_from_file(data_symbol, keys=data_expected.keys())
for field, value in data_expected.items():
self.assertEqual(data[field], value)
# clean up cache
self.clean_cache_for_symbol(data_symbol)
Run the test and see it fail:
AssertionError: 255.02 != 255.0
Well, this was expected, since no caching functionality has been implemented yet. Let’s add the caching capability.
Implement cache
I will have to add the caching capability to the stock data provider level, which are the read_from_stock_file and read_from_yahoo_finance_api functions.
Starting with the local provider, I will create a wrapper function read_from_stock_file_with_cache that will handle the cache related logic and call read_from_stock_file to get the latest data if cache is not valid:
def read_from_stock_file(symbol):
filename = local_filename_for_symbol(symbol)
try:
with open(filename, 'r') as f:
return f.read()
except Exception as e:
print("ERROR: could not read file {}: {}".format(filename, repr(e)))
return None
def read_from_stock_file_with_cache(symbol):
cache_ttl = 15 # hardcode this for now, set to 0 to disable cache
if cache_ttl > 0:
cache_filename = cache_filename_for_symbol(symbol)
if cache_filename:
try:
cache_timestamp = os.path.getmtime(cache_filename)
now = time.time()
if (now - cache_timestamp) < cache_ttl:
# cache hit, return cache data
print("INFO: cache hit")
with open(cache_filename, 'r') as f:
return f.read()
except FileNotFoundError as e:
pass
except Exception as e:
print("WARNING: could not read cache file {}: {}".format(cache_filename, repr(e)))
# cache miss or disabled, get current data, cache and return
data = read_from_stock_file(symbol)
if cache_ttl > 0:
print("INFO: cache miss")
if cache_filename and data:
try:
with open(cache_filename, 'w') as f:
f.write(data)
except Exception as e:
print("WARNING: could not write cache file {}: {}".format(cache_filename, repr(e)))
return data
And, I will change the get_stock_data_from_file function to call the read_from_stock_file_with_cache instead:
def get_stock_data_from_file(symbol, keys=None): data = read_from_stock_file_with_cache(symbol) return get_stock_info_from_data(data, symbol, keys)
Running the tests again, I see that it worked:
python test.py ...... ---------------------------------------------------------------------- Ran 6 tests in 0.603s OK
Tests for cache miss and cache creation
To test for cache miss, the code is exactly the same, except that I manually change the cache file modification time to be old enough for the cache to miss, and I expect to get the “current” data back.
The final test case aims to make sure that after a cache miss, the data is cached correctly and a subsequent call with result in a cache hit
def test_cache_exists_and_expired(self):
data_symbol = self.params['data_symbol']
# setup cache environment
self.clean_cache_for_symbol(data_symbol)
cache_target_filename = stock.cache_filename_for_symbol(data_symbol)
# the cache file is just created here, so it's definitely new
shutil.copy(self.params['data_cache_miss_filename'], cache_target_filename)
# the modification time must be changed to be old enough for cache to miss
old_enough_time = time.time() - 3600
os.utime(cache_target_filename, (old_enough_time, old_enough_time))
# start test
data_expected = self.params['data']
data = stock.get_stock_data_from_file(data_symbol, data_expected.keys())
for field, value in data_expected.items():
self.assertEqual(data[field], value)
# clean up cache
self.clean_cache_for_symbol(data_symbol)
def test_cache_missing_and_created(self):
data_symbol = self.params['data_symbol']
# setup cache environment
self.clean_cache_for_symbol(data_symbol)
# start test
data_expected = self.params['data']
data = stock.get_stock_data_from_file(data_symbol, data_expected.keys())
for field, value in data_expected.items():
self.assertEqual(data[field], value)
# check if cache file exists
self.assertTrue(os.path.exists(stock.cache_filename_for_symbol(data_symbol)))
# clean up cache
self.clean_cache_for_symbol(data_symbol)
Final test run, with success:
python test.py ........ ---------------------------------------------------------------------- Ran 8 tests in 0.721s OK
Again, an issue leads to a design pattern
The caching mechanism seems to work fine so far, but what about when actually reading from the API?
For the local sample files source case, I wrote a new function read_from_stock_file_with_cache and I changed the implementation of function get_stock_data_from_file to use it. Should I do that again for the API source case? It seems like a lot of code repetition for almost the same functionality. Is there a way to do this more elegantly, in a reusable and transparent way?
It seems that there is. I will use the Decorator Pattern.
With this, I will create a wrapper function that will augment my data read functions with the caching mechanism and redefine the original functions to point to this new wrapper function. The caching mechanism will be transparent, no change will be needed at the get_stock_data_from_* methods.
The decorator pattern looks like this:
def decorator(original_func): def wrapper_function(params): # do something original_func(params) # do something more return wrapper_function some_function = decorator(some_function)
Let’s define the decorator function in stock.py (reusing the code that we already wrote):
def stock_cache(func):
def wrapper_function(symbol):
cache_ttl = 15 # hardcode for now, set to 0 to disable cache
if cache_ttl > 0:
cache_filename = cache_filename_for_symbol(symbol)
if cache_filename:
try:
cache_timestamp = os.path.getmtime(cache_filename)
now = time.time()
if (now - cache_timestamp) < cache_ttl:
# cache hit, return cache data
print("INFO: cache hit")
with open(cache_filename, 'r') as f:
return f.read()
except FileNotFoundError as e:
pass
except Exception as e:
print("WARNING: could not read cache file {}: {}".format(cache_filename, repr(e)))
# cache miss or disabled, get current data, cache and return
data = func(symbol) # <-- call original function
if cache_ttl > 0:
print("INFO: cache miss")
if cache_filename and data:
try:
with open(cache_filename, 'w') as f:
f.write(data)
except Exception as e:
print("WARNING: could not write cache file {}: {}".format(cache_filename, repr(e)))
return data
return wrapper_function
Notice the calling of the original function in the middle of the code. This is the same logic as in the specific wrapper function read_from_stock_file_with_cache, only this time the wrapper function is more generic and can be applied to any stock data provider function.
Also notice that I have hardcoded the cache expiration duration, having in mind that in the future I will probably want to parametrize that (or maybe disable caching altogether in special cases).
Now, I can redefine the read_from_stock_file to become decorated by stock_cache:
read_from_stock_file = stock_cache(read_from_stock_file)
Or, using the python syntactic sugar for decoration, I can simply put @stock_cache above the function definition:
@stock_cache def read_from_stock_file(symbol):
Those syntaxes are effectively equivalent.
I will then delete the function read_from_stock_file_with_cache which is no longer needed, and change get_stock_data_from_file back to the way it was, as it will now use the cache decorated read_from_stock_file function:
def get_stock_data_from_file(symbol, keys=None): data = read_from_stock_file(symbol) return get_stock_info_from_data(data, symbol, keys)
Boldly run the tests again:
python test.py ........ ---------------------------------------------------------------------- Ran 8 tests in 0.776s OK
Decorate the API function as well
Having a working cache decorator, I can easily apply the pattern to the API reader function as well:
@stock_cache def read_from_yahoo_finance_api(symbol): # ...
And I now have caching enabled for the API, just like that!
If I decide to change the caching mechanism in the future, I will just rewrite the decorator to implement that.
Run the Azure Function locally
Since I haven’t changed the interface of the get_stock_data_from_api function that I used in the previous implementation of the HttpTrigger1 Azure Function, I should not need to change anything to make it work in Azure, right?
Well, let’s try running the Function locally first, call HttpTrigger a couple of times and see the output:
func start curl http://localhost:7071/api/HttpTrigger1?symbol=MSFT curl http://localhost:7071/api/HttpTrigger1?symbol=MSFT
The console output is:
func start
Found Python version 3.10.6 (python3).
Azure Functions Core Tools
Core Tools Version: 4.0.4895 Commit hash: N/A (64-bit)
Function Runtime Version: 4.13.0.19486
Functions:
HttpTrigger1: [GET,POST] http://localhost:7071/api/HttpTrigger1
For detailed output, run func with --verbose flag.
[2022-12-10T23:29:06.392Z] Worker process started and initialized.
[2022-12-10T23:29:11.097Z] Host lock lease acquired by instance ID '00000000000000000000000080AAF36A'.
[2022-12-10T23:29:12.578Z] Executing 'Functions.HttpTrigger1' (Reason='This function was programmatically called via the host APIs.', Id=a955d8cf-07ad-4845-b8e2-e5dfb2644efb)
[2022-12-10T23:29:12.597Z] Python HTTP trigger function processed a request.
[2022-12-10T23:29:13.071Z] INFO: cache miss
[2022-12-10T23:29:13.071Z] Executed 'Functions.HttpTrigger1' (Succeeded, Id=a955d8cf-07ad-4845-b8e2-e5dfb2644efb, Duration=493ms)
[2022-12-10T23:29:14.179Z] Executing 'Functions.HttpTrigger1' (Reason='This function was programmatically called via the host APIs.', Id=adcf6f01-e8f3-4130-9af8-db7271a9824f)
[2022-12-10T23:29:14.184Z] Python HTTP trigger function processed a request.
[2022-12-10T23:29:14.185Z] INFO: cache hit
[2022-12-10T23:29:14.187Z] Executed 'Functions.HttpTrigger1' (Succeeded, Id=adcf6f01-e8f3-4130-9af8-db7271a9824f, Duration=7ms)
I see an INFO: cache miss message for the first call and an INFO: cache hit for the second call, so the caching mechanism seems to work when running the Function locally.
Move the logic to Azure (and fail, miserably)
Let’s publish it to Azure and see how it goes there. I will update the .funcignore file to exclude any files that should not be copied to Azure, and publish the Azure Function App:
.vscode/ .venv/ tests/ local.settings.json *_sample_*.json *_local.json *_cached.json test.py get_stock_price.py getting_started.md README.md
Now, before calling the function URL, I will open up the Function Monitor and Live Metrics:

After calling the Function URL a couple of times and getting the expected HTML output in my browser, here’s what I see in the Live Metrics Window:
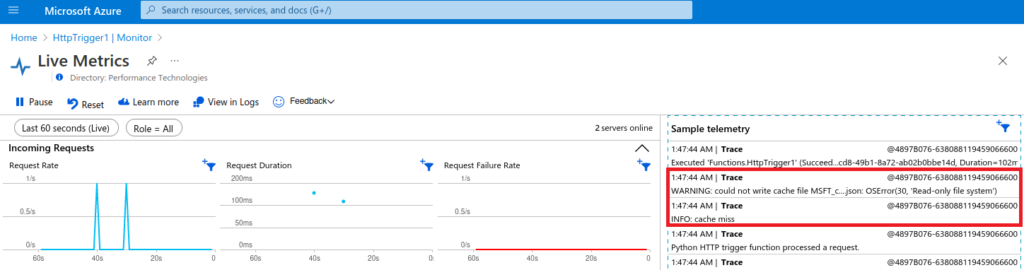
Well, it seems that the caching mechanism I implemented doesn’t work in Azure… The error message reads:
WARNING: could not write cache file MSFT_cached.json: OSError(30, 'Read-only file system')
Fail, research, refactor, retry
Let’s see why the naïve cache implementation with local files failed.
From the documentation at Azure Functions Reference for Python, I find some important information:
- In Azure Functions, one can’t use the file system like in a Virtual Machine or Container. The Function directory is read-only.
- There is still a way to store temporary files, but it has to be in the temporary folder (
/tmpin Linux) - Files written to the temporary directory aren’t guaranteed to persist between subsequent invocations of the Function. Also, temporary files aren’t shared between scaled instances.
Well, let’s try a quick fix based on the above. Since I don’t really need cache to persist for a long time (not more than 15 seconds), what about saving the cache files to the temporary storage? A Function that is invoked frequently enough to benefit from caching, will probably stay loaded in the same environment by Azure anyway, so it will effectively have a persistent temporary directory.
I’ll make a quick fix in the cache_filename_for_symbol function to construct filenames in the temporary folder:
import tempfile def cache_filename_for_symbol(symbol: str) -> Optional[str]: """Returns cache filename in temporary folder that corresponds to specified symbol.""" tmppath = tempfile.gettempdir() return tmppath + '/' + STOCK_CACHE_FILENAME_PATTERN.format(symbol) if is_valid_symbol(symbol) else None
Let’s publish again in Azure and try the same steps as before:
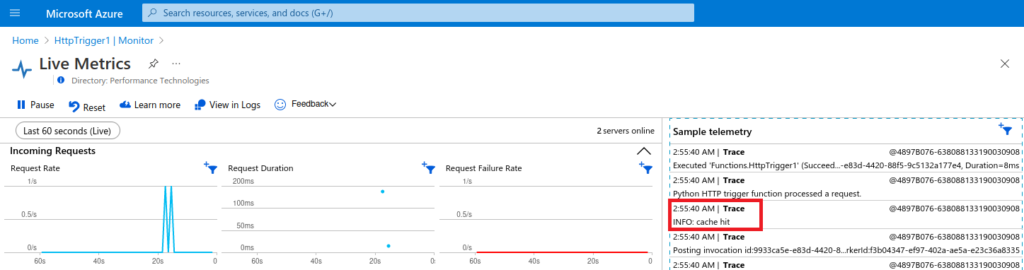
And it works! I see a cache hit and no file related errors.
Make it better
So, I found a way to make the naïve caching mechanism work. But this isn’t enough. The Lab must go on! 🙂
In the next episode of this Late Night Lab, I will try to implement alternative caching mechanisms and learn more in the process! Until then, take care and keep coding!